
Building a Semantic Parser and Parsing Queries About Song Data with SEMPRE
Published:
Summary
Semantic parsers allow users to interact with data using natural language. Think of a very basic chatbot where a user can ask a question using whatever language they want about a specific database, and the parser will try to translate that natural language into logical queries, then provide an answer. This is not an easy task. Natural language isn’t perfectly logical and is full of ambiguities – that’s what makes it natural!
Using the SEMPRE framework, we developed a semantic parser which queries a small subset of the Million Song Dataset as a group project for the Natural Language Understanding and Computational Semantics course at the New York University Center for Data Science in spring 2019. More details about the parser can be found in the Methods section below. Our report can be found here, and relevant code can be found in this repo on Github.
Methods: We trained a log-linear model to assign probabilities to potential logical queries given a natural language query, using the SEMPRE framework. To do this, we generated several examples of logical queries and natural language paraphrases of those queries.
One question that I explored was how different linguistic features affected the performance of the model. SEMPRE has support built into it for several sets of features, ranging from fairly straightforward ones like the count of unique tokens to more complex ideas like the use of a paraphrase database or alignment scores with the Berkeley aligner. In particular, we found that the best performance was achieved with all features except for the count of unaligned tokens between the query and a potential logical parse. It’s possible that such information might be better captured by features related to alignment scores and common words or tokens.
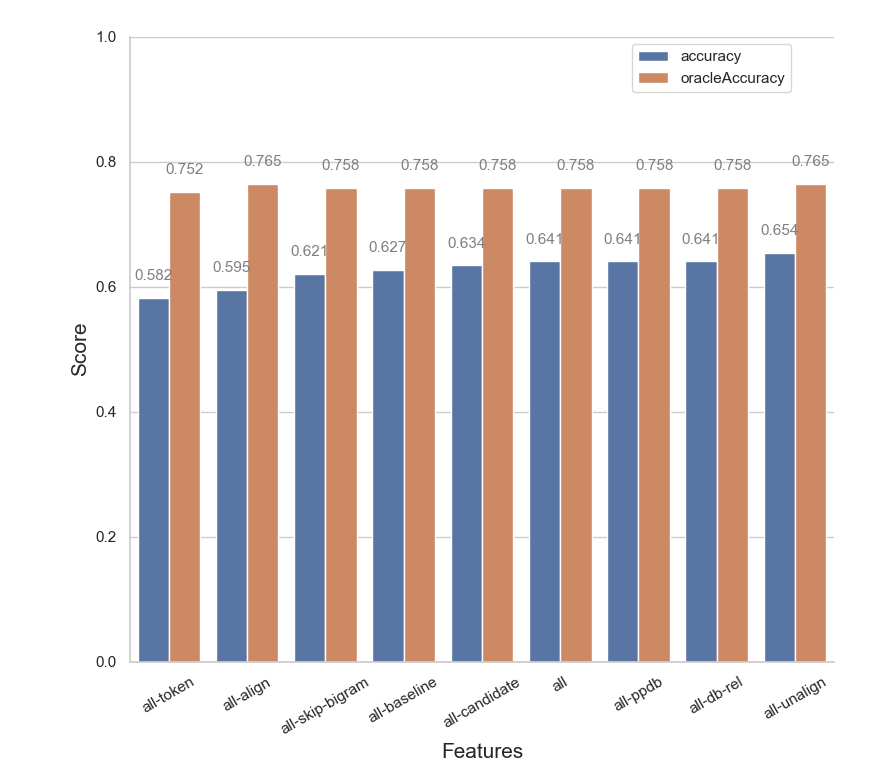
Other experiments were also simple but insightful. The model benefits from seeing diverse logical queries during training but benefits less from seeing different natural language paraphrases of those queries. When a particular type of query is not present in the training dataset, the model cannot parse natural language paraphrases of that query at test time.
Challenges, Limitations, and Learning: In our error analysis, we noted that our model performed poorly with understanding types of queries that it had not seen during training. This is largely expected behavior, though it is still worth noting. Training and evaluating the model on a relatively small dataset with only about 1000 relationships took more than an hour; this model may not scale vey well to much larger datasets. From a more logistical standpoint, I personally did not know Java very well at the start of this project; since SEMPRE is primarily written in Java, I had to learn more about the Java language structure and syntax on the fly in addition to learning about the models.
Collaborators: I collaborated with Arushi Himatsingka, Brina Seidel, and Marina Zavalina. This course was taught by Professor Sam Bowman and Professor Katharina Kann.